Data for a product demonstration
We’ve written a project or some part of its logic, but now there is an issue: how can we demonstrate the success of what we’ve produced? We don’t have the actual data which will eventually be used with the project, yet we need to fill it with content which we can use to look at how everything functions, which features work well and which need adjusting and so on. At first the solution seems obvious, we need to find a “content-manager”, describe to them the sort of data required and they can then come up with appropriate content to test and demonstrate the program. Those who’ve done this at least once understand that it’s not quite so simple.
A complicated task
Just imagine: to show the full capabilities of our system, we need to create a minimum of 10 users, each consisting of a full data set (potentially including but not limited to name, surname, date of birth,e-mail, phone number, city of birth, city of residence, post code, current geographic coordinates, current ip-address, website and much more). As you can see you need to think up a lot of information and it has to look very similar to real user data. This is where the problems start, our system content isn’t limited only to users, we might also have some other things which the users interact with, for example products, which in turn may have their own dependencies, for example categories. Of course these products and categories also need to be created for demonstration purposes, names need to be thought up, characteristics, the list goes on. What looked at first glance like a pretty simple task has somehow turned into a big problem.
The plot thickens
So supposing our content-manager thinks up all the names, characteristics and other information and we have all the basic content we need. We make a presentation of our project as is to the customer, naturally they’re pleased and everyone is happy. But there are still challenges ahead for us.
After that initial presentation we find some bugs and of course the project will continue to be developed further. Parallel to this, our QAs are testing the app constantly. What does that mean? They test all the different functions: for changing names, addresses, passwords and so on. Adding, deleting, and renaming the product and category information. Eventually at some point the status of our content is likely to become unreadable and illogical.
Cleanup time
Of course the next presentation of our work is not far off and you can probably guess what that means! We have 2 options:
1) we try to clean up our existing content so that it becomes presentable again. Depending on the scope, extent of damage and maybe some other things, this option can take a very long time.
2) we completely clean our database and think up new content that matches the requirements of the fixed/improved program (making our content manager extremely happy along the way).
The need for testing data
There is one more version of this problem, which applies more to the process of developing and the needs of the developer. A good habit to develop is, parallel with writing an application’s code, writing it’s test. For testing php code we usually use the very strong framework phpUnit. There are different methods and types of testing. For example, when we’re working on the API of our app, of course we want to completely cover it with tests, at least the most critical areas. Functional tests can make in-test requests to our API, receive answers and check the results. But if we want to test something we again need to have content for the program to interact with. Furthermore it’s good practice to run each test using the same data, so that the test environment stays consistent. But some requests can change the data in our app, for example a test for updating the user profile.
Again we find ourselves with a similar problem. We could update the data in our database after each test, but this just creates an unreal workload and additionally spoils our data for the upcoming presentation. Notice that there is another solution here, tests can be set in such a way that at the start of each test the database is deleted and new testing data recorded, but this is a topic for another discussion, today I’d like to look at a different solution.
Generating data in Symfony
Symfony wouldn’t be Symfony if it didn’t help us to cope with these tasks. I’ve given quite a bit of context to the problem, so now I think it’s time to show how to solve the problem of demo content using Symfony.
In Symfony there is the notion of “fixtures” – this is a tool for the creation of demo data. But using the standard solution available inside Symfony is not very comfortable. Instead there is cool tool called AliceBundle, which will help us complete our task. To install it you have to write in your console: composer require –dev hautelook/alice-bundle and then activate the bundle in the file app/AppKernel.php
Add the following to the $bundles array (dev. section):
$bundles[] = new DoctrineBundleFixturesBundleDoctrineFixturesBundle();
$bundles[] = new HautelookAliceBundleHautelookAliceBundle();
Now everything is ready to begin writing our demo data.
Ready to begin
There is a standard practice regarding file allocation which we need.
In the root of our bundle we create a directory called DataFixtures. If in our project we use a relational database (eg. MySql, MariaDb, PostgreSql) we create an ODM directory in the DataFixtures directory. If we’re using a non-relational database (eg. MongoDb, CouchDb), then we simply create an ODM directory as well. We need to have a fixtures class loader (FixtureLoader) in one of these directories.
Here’s an example of this file:
The point of this file is to show which files need fixtures, in what order and where to download from.
I prefer fixture files to be in corresponding directories: Data – for our regular site fixtures, presentations and QA. DataForTests – for our tests. Here’s an examples of what that directory structure could look like:
When downloading fixtures, the loader determines the environment. So if we run tests, the environment will be “test” and will load the corresponding files with the specially prepared fixtures for tests which we wrote. In all other cases regular fixtures are loaded.
Notice! When we download fixtures to our database, it gets cleared before the start of the operation every time. That’s why for tests we don’t usually use our main database, but something simpler and easier to use, (eg. SQLite). That way we avoid violating the integrity of our main database. To configure an alternate database for the tests we need to properly configure a test environment, we can do this from app/config/config_test.yml
Here’s an example of what that configuration might look like (just looking at the part of the configuration relevant to databases)
Above I said that for the test environment I often use SQLite and detailed where it should be located and so on. In other environments we just use the standard settings.
Now, to the fixtures themselves. For writing them we use the yaml format and some specific syntax. I strongly suggest reading the documentation connected to the bundle (link above), to get a better idea of the details. Here I’m just going to give an example fixture and show the results.
For the example I use the following relational structure between our entities: we have a user, who can have a lot of products, every product can have only one owner. A product can have several pre-established categories and tags, categories and tags can be the same for different products. It should also be mentioned that Alice can only create objects for and load data to the structure that we have described.
Now the question is, which data do we need to load and where will we get it from? In Alice there’s a third party library specifically for generating this data, it’s called Faker. I recommend that you familiarize yourself more thoroughly with the opportunities Faker provides, but the brief version is this: it’s a library that can generate a lot of different data, for example everything connected to a user – name, surname, gender, and so on.
Now for some examples of fixtures:
– tag :
This generates 80 tags with different names.
– categories:
This generates 150 (!) categories with different names. Four simple lines and you get 150 objects ready for the database! Take note, in the example I gave the constructor was deactivated, this can be useful when you have external dependencies, but for fixtures it’s not important.
– users and products :
This generate 30 users with full information and 20 products, each users is added randomly assigned 2 products. Each product is also assigned some random categories and tags which we created before.
To generate fixtures we need to execute the console command:
app/console doctrine:fixtures:load -n
You can see the results of our work in these screenshots: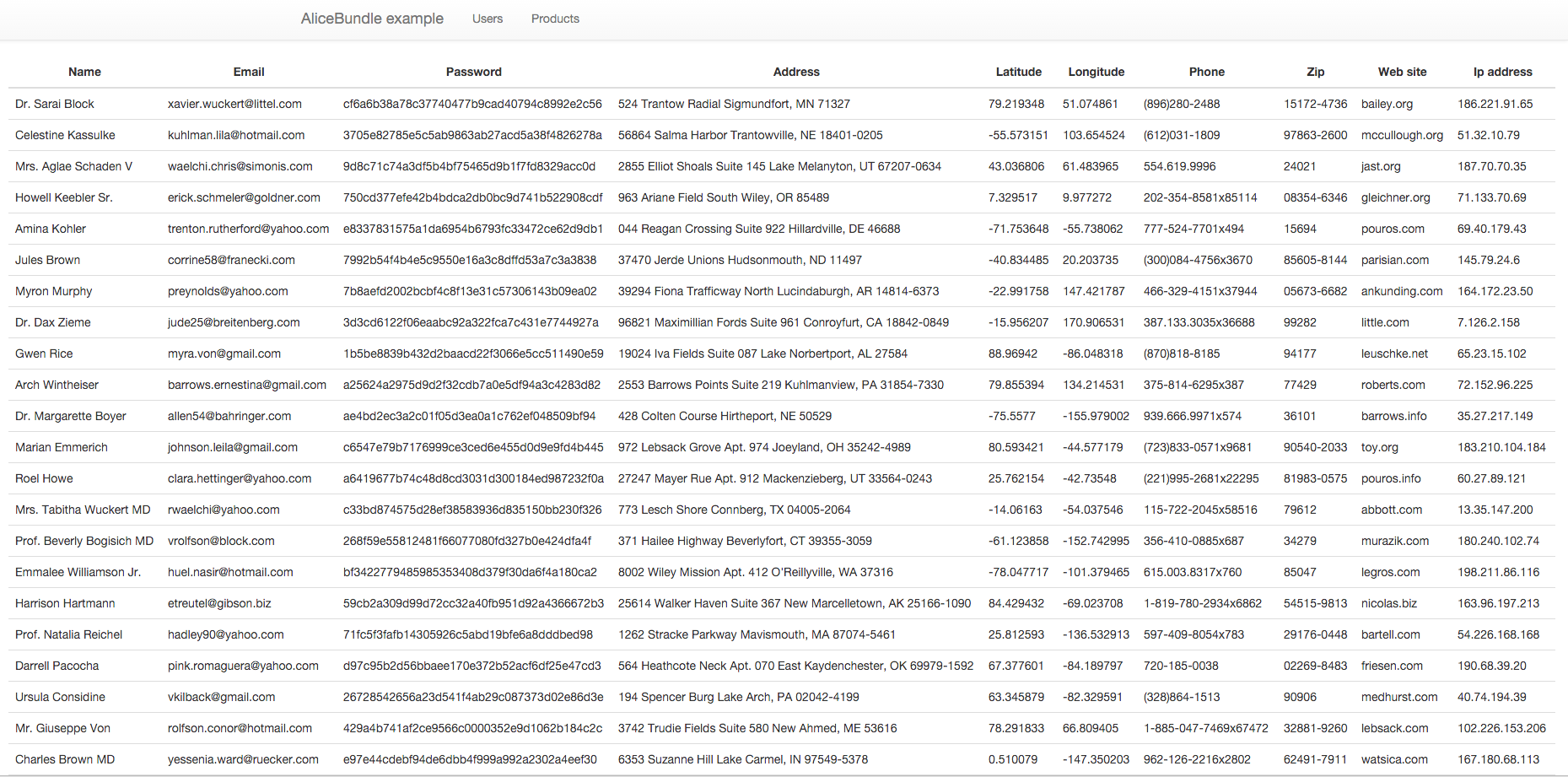
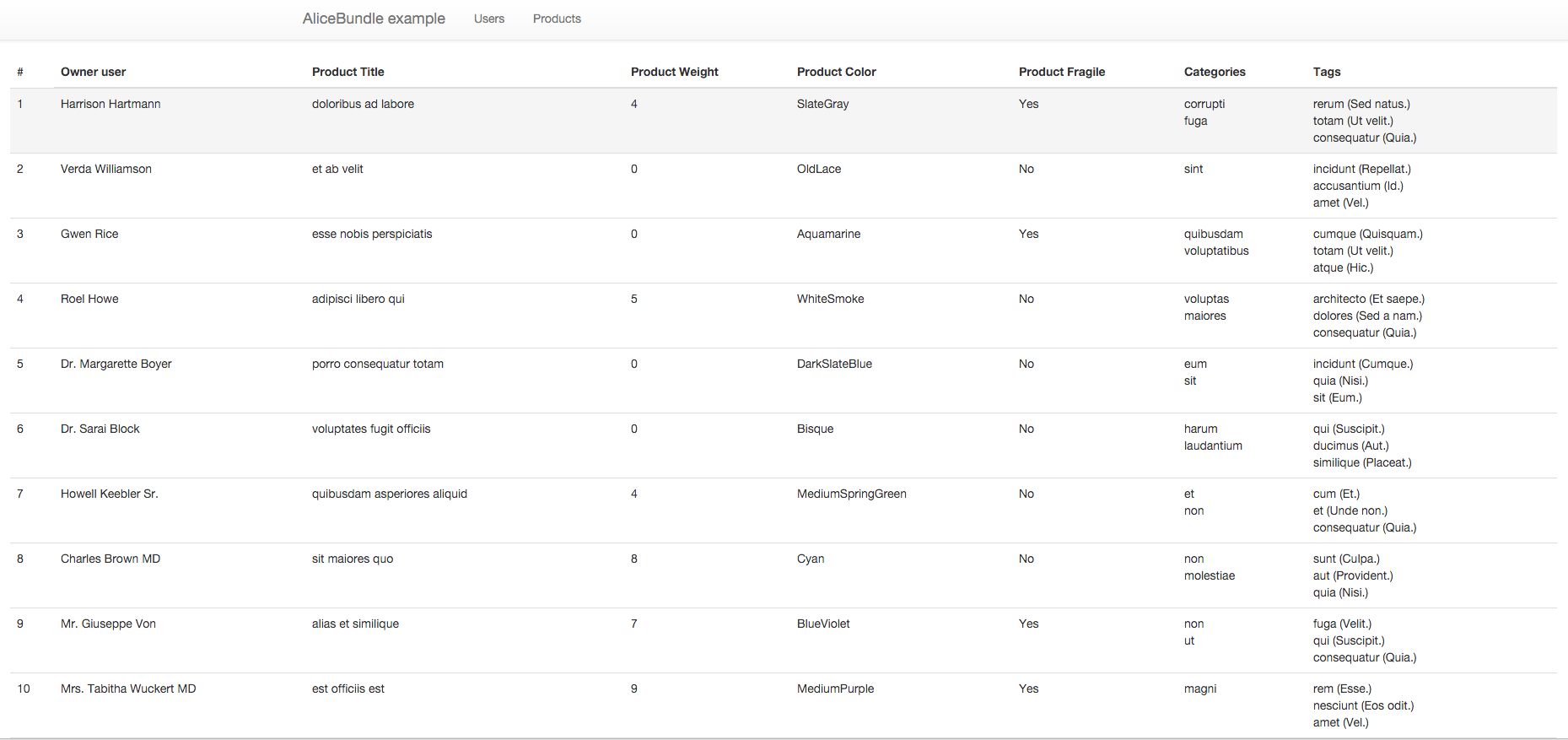
On the screenshot of users I included a password, which was also generated by Faker, specifically using the <sha1()> instruction. If we try to use this data for a real login of course it won’t work for us, because the password doesn’t comply with Symfony. But it’s not a problem, we can write custom instructions for generating data. Here’s an example in which legitimate passwords are generated, so you can login with this data or run tests.
Custom instructions should be placed in the class-loader fixture “FixtureLoader”. They can then be used as follows:
In this way, all users get a correctly generated password of “123”, that we can use to login to the accounts.
So when needed we can write our own instructions without using Faker.
What have we got in the end? We have written very little code, yet what we’ve written can generate a lot of data for testing, for making presentations or any other use. Moreover, we’ve saved our content manager many hours of tedium. Also we’ve improved the quality of our code and of our application in general.
Thanks!




Related Posts
Agentic Teams vs Sub-Agents: The AI Architecture Decision Most Teams Get Wrong
Why the difference between “more agents” and “better thinking” quietly determines whether your AI investment compounds, or stalls out The…

IoT and Wearables in Healthcare: Transforming Patient Care with Mobile Apps
In today’s fast-paced world, the healthcare industry is constantly evolving, driven by technological advancements that have the potential to transform…

Why your web or mobile app needs a regular security audit
Despite the obvious risks to a technology based business posed by hackers, phishers and other bad actors, sometimes a project’s…